
Navigating Resiliency Patterns: SRE System Design Recommendations
We all like failures that are handled and the impact is minimized during incidents; and Resiliency patterns support this very cause with creative methods.

In today's digitally connected world, where downtime is often synonymous with lost opportunities and revenue, Site Reliability Engineers (SREs) play a pivotal role in ensuring the reliability and availability of online services. They achieve this by implementing various resiliency patterns that can prevent or gracefully handle failures. In this article, we'll explore some essential resiliency patterns that every SRE should be familiar with.
Site Reliability Engineers (SREs) are responsible for ensuring the reliability and performance of large-scale software systems. One of the key ways that SREs achieve this is by using resiliency patterns.
Resiliency patterns are a set of design principles and best practices that can be used to build and operate systems that are able to withstand failures and disruptions.
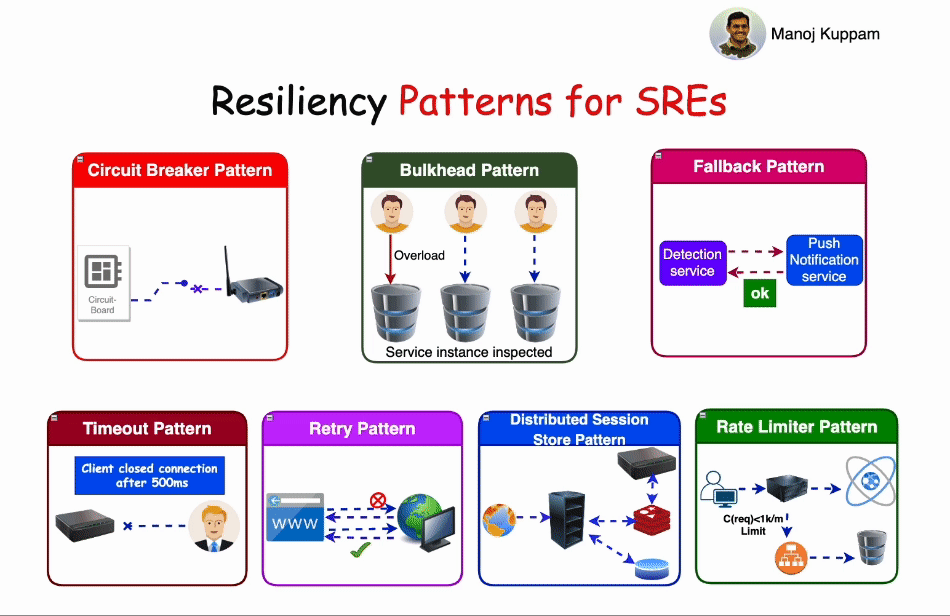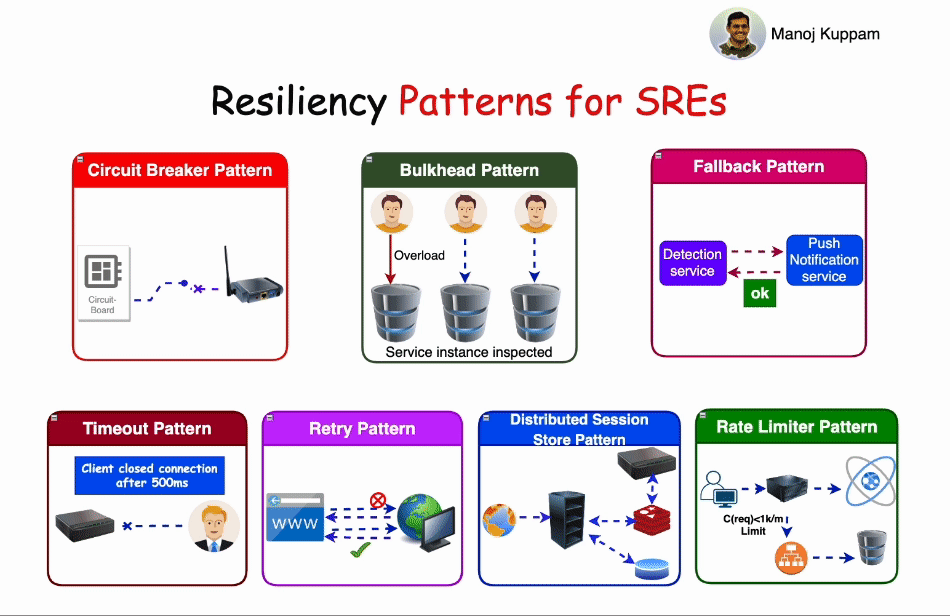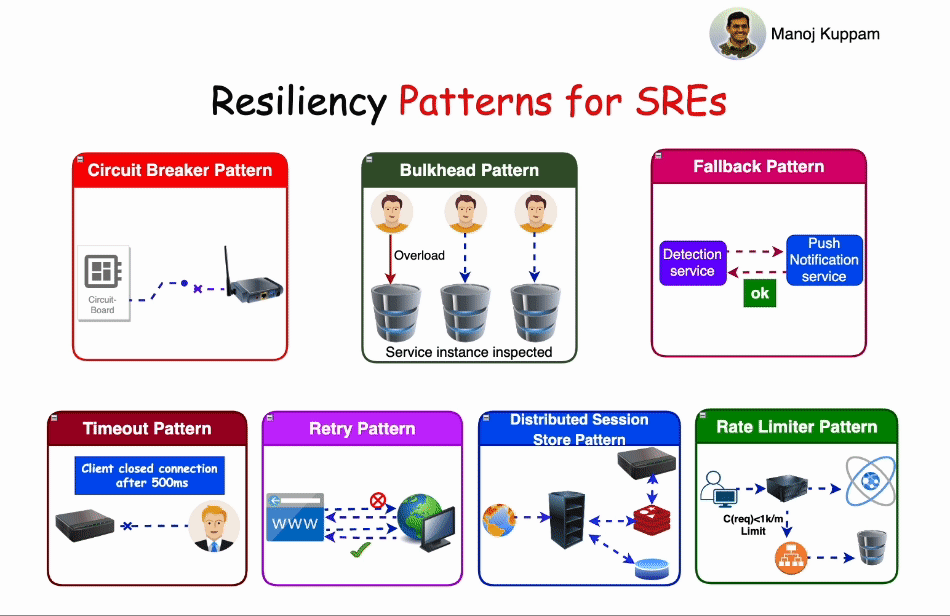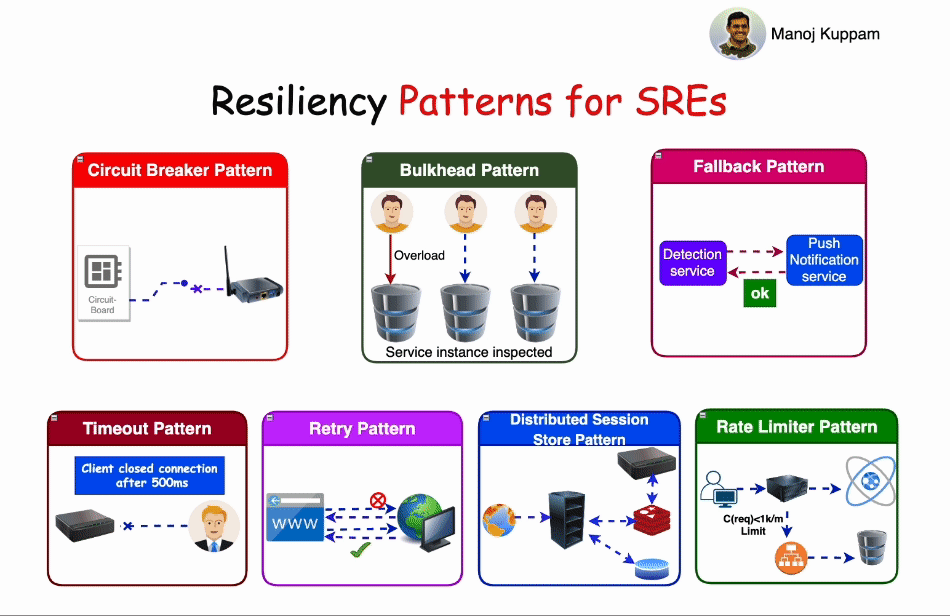
Some of the most common resiliency patterns include:
1. Circuit Breaker Pattern:
The Circuit Breaker pattern operates much like an electrical circuit breaker. When a service experiences repeated failures or timeouts, the circuit breaker trips, temporarily stopping requests to that service. This prevents cascading failures, reduces load, and gives the service time to recover. Circuit breakers can be configured to periodically test the failed service to determine if it has recovered.
2. Bulkhead Pattern:
Bulkheads, inspired by ship design, segregate components or services to limit the impact of one failing component on the entire system. In an application context, bulkheads ensure that a failure in one part of a system doesn't lead to the failure of another, keeping services isolated and reducing the scope of potential damage.
3. Fallback Pattern:
Fallback patterns involve providing alternative solutions or responses when a primary service is unavailable. This is especially useful for maintaining a basic level of service even in the face of partial service degradation. Fallbacks might include using cached data or a simplified version of the functionality.
4. Timeout Pattern:
Timeout patterns define the maximum acceptable time for a request to receive a response. If a response isn't received within this timeframe, the system can take action, such as retrying the request, serving a fallback response, or escalating the issue.
5. Retry Pattern:
The Retry pattern involves automatically retrying a failed request to a service, hoping for a successful response. Retries can be configured with backoff strategies, where each subsequent retry increases the delay between attempts. This pattern helps mitigate transient failures and can be especially useful when combined with circuit breakers.
6. Distributed Session Store Pattern:
In a distributed system, maintaining user sessions across multiple services can be challenging. The Distributed Session Store pattern involves using a shared session store, often backed by a distributed database, to ensure session data remains consistent and accessible across services, even if some of them fail.
7. Rate Limiter Pattern:
Rate limiting is a critical resiliency pattern that prevents overloading a service by restricting the number of requests it can handle within a specific time frame. This pattern helps maintain service performance, protects against abuse, and can be used to prioritize different types of traffic.
Each of these resiliency patterns is a valuable tool in the SRE's toolkit, helping ensure that systems remain robust and responsive, even in the face of adversity. SREs must carefully select and apply these patterns, considering the specific requirements of their services and the potential impact of different failure scenarios.
SREs can use these and other resiliency patterns to build and operate systems that are more reliable and resilient to failures.
Here are some examples of how these resiliency patterns can be used in practice:
• A circuit breaker can be used to protect a microservices architecture from cascading failures.
• A bulkhead can be used to isolate a critical service from other services so that it is not affected by failures in those services.
• A fallback can be used to provide a backup plan for a critical service in case it fails.
• A timeout can be used to prevent the system from being blocked by requests that take a long time to complete.
• A retry can be used to automatically retry requests that fail due to transient errors.
• A distributed session store can be used to store session data in a way that is resilient to failures.
• A rate limiter can be used to prevent the system from being overloaded by a large number of requests.
"Auto Scaling" and "Stateless Services" are two tactics that support resiliency in the context of Site Reliability Engineering (SRE):
Auto Scaling:
Auto scaling is a crucial tactic that complements resiliency patterns. It enables your infrastructure to adapt to varying workloads by automatically increasing or decreasing the number of instances based on demand. When traffic surges, such as during a sudden traffic spike or high demand, auto scaling ensures that your system can handle the increased load without performance degradation.
The beauty of auto scaling lies in its ability to maintain optimal resource utilization and minimize costs during periods of lower demand. Cloud providers offer auto scaling features that allow SREs to define scaling policies and thresholds. This tactic not only enhances resiliency by handling fluctuations in traffic but also ensures efficient resource allocation, making it a cost-effective solution.
Stateless Services:
Stateless services are a fundamental tactic that supports resiliency. In a stateless architecture, each service or component operates without relying on shared or persistent state information. Instead, all necessary data is contained within the request or operation itself. Stateless services are designed to treat each request independently, without retaining session or user-specific data between requests.
The advantage of stateless services is that they can be easily replaced or scaled up without worrying about the state or data associated with a particular instance. In the event of a failure, the system can quickly switch to a backup or new instance without affecting the user experience. This approach simplifies failover strategies and reduces the impact of service interruptions.
By embracing both auto scaling and stateless services, SREs can bolster their resiliency efforts. Auto scaling ensures that the system can dynamically adapt to changes in traffic, while stateless services make it easier to recover from failures and ensure seamless user experiences, even in the face of service disruptions. These tactics work hand-in-hand with resiliency patterns to create a comprehensive strategy for ensuring system reliability and availability.